
Backing up a Ghost blog (or anything) on AWS EC2 to S3
code

So you have a ghost blog(or some other amazon web thing), and you're on AWS ubuntu (or another Linux type instance) but you need to back it up. It would seem simple that AWS should offer you a solution, and there is one, just follow these steps:
Pt 1 - Easy Version
Using the AWS command line from the EC2 instance in question we can send files to (and from) a bucket in s3:
1.
Make sure you have an AWS IAM role, I made an account just for this job and I used that.
2.
Make sure you get the access keys for that IAM Role (put them somewhere safe) from the IAM console keys section (IAM > Users > Backup Role > Security Creds tab > Create access Key)
3.
Make your bucket in the s3 console, name it something useful you'll remember.
4.
Log in to your EC2 instance, using ssh & the keys that were given to you when you launched the instance (I use putty, this is a good tutorial)
5.
Make sure you have python (it comes on all the EC2 instances anyways):
1python -V
6.
Make sure you have pip:
1pip -V
... Don't have it? install it:
1sudo apt-get install python-pip
7.
Make sure you have aws-cli:
1aws --version
... don't have it? install it:
1pip install awscli
8.
Now we need to set up the aws-cli for the IAM user who will be backing up the stuff... Hopefully, we haven't lost the keys from step #### 2. Now run the command
1aws configure
it will give you something like the below... fill this in with the details you got in step 2.
1 2 3 4AWS Access Key ID \[None\]: <YOUR_ID> AWS Secret Access Key \[None\]: <YOUR_SECRET> Default region name \[None\]: <YOUR_REGION> Default output format \[None\]: json
9.
Right, now we are set up we can use the aws s3 cp command to copy things around the place using their API.
10.
Navigate to the directory you want to back up, something like /var/www/ghost/content then we can run the command:
1aws s3 cp ./ s3://bucket_name --recursive --dryrun
11.
This should spit a bunch of stuff onto the screen saying it's copying the files, and you're done! (not really)... the --dryrun option just shows you what it would be doing; remove that, run it again and **YOU'RE DONE!!**
Make sure you check your bucket, it should come out like this:
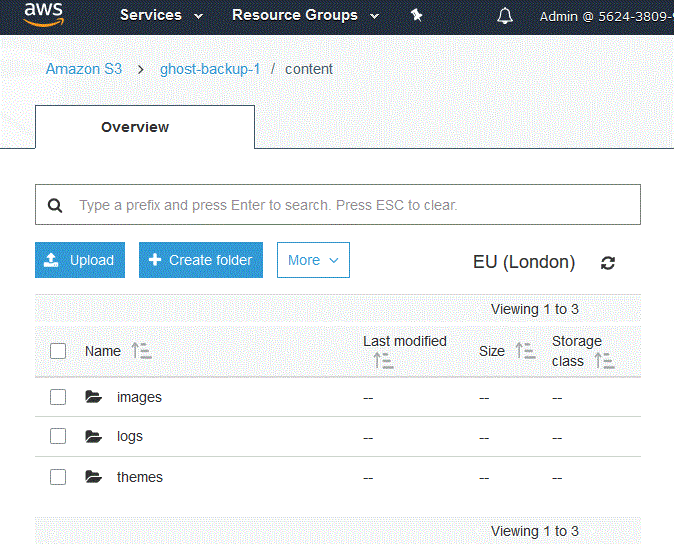
Pt 2 - Use git!
I was thinking, were just moving stuff around to other storage facilities, wouldn't it be lovely to keep it all in place I'm super good with restoring and moving files about? What do I use that does this all the time? GIT!
After some thought, it was simple, in fact, if you understand git the idea alone should be enough to understand what you need to go do. If not I have provided a step by step below of the steps I took to reposetrize my ghost blog.
1.
Go to your origin git location, like, say github, gitlab, or any of the many others (I used GitLab, its private by default & the logs should probably not be public) and create a repo like ghost-backup
2.
SSH into your computer using PuTTY or some other SSH client, just like when using aws-cli.
3.
Nav to the content files, usually cd /var/www/ghost/content
4.
Now, we can run the following commands in turn to create a repo, set its origin (remember to change this bit), add the files to a commit, commit them and push to your origin. shall we begin?
sudo git init sudo git remote add origin https://#git-origin-domain.com#/#username#/#project-name.git# sudo git add . sudo git commit -m "Initial commit" sudo git push -u origin master
Hey presto, and you're done! your origin will now have a bunch of easily viewable content, this could potentially be shoved into a cron job with some SSH keys to automate this process of committing and pushing to a remote. Below has some ideas that solve this problem.
Pt 3 - Auto Backups
Crontabs are amazing, they're little bits of code that you can make them run every now and then. we can leverage that to run an s3 command every week!
Firstly we want to build the shell script which will back the site up; it can live anywhere, just remember where it is. I keep mine in the same folder as the ghost content (for reasons to do with backing up the script also when using git). Here's what were going to do:
1.
nav to the directory: cd /path/to/dir/
2.
create file sudo touch ./backup.sh
3.
Edit the file sudo nano ./backup.sh and add:
1 2 3 4cd /var/www/ghost/content/ aws s3 cp ./images s3://ghost-backup/images --recursive --dryrun aws s3 cp ./data s3://ghost-backup/data --recursive --dryrun
This will nav to the content folder of ghost, then send the data & images to the s3 bucket (which has to be pre-built, see the section above on how to do that). If you remove the --dryrun command from the lines this will go live and actually push the files, for testing so it's fine to leave it in but it won't actually do any copying when run.
Running sudo sh /path/to/dir/file.sh should now dry-run your backup script & have a bunch of output. It will be telling you how much stuff is moving about. This should be just your images & data; this will cost a little bit on AWS so make sure you're not coping with millions of items! If it's working then great we can move on to setting up a crontab for the shell script.
The command sudo crontab -e will let you edit the root users crontab, so everything that runs will have the highest permissions. Here we can add the path to our shell script (or whatever other script you want) that will back up the site. By adding 0 0 * * 0 sudo sh /path/to/dir/file.sh to the crontab. We will be running the script every week on a Sunday. This question has lots of answers to how to schedule the scripts.
Personally, I tested the system with the --dryrun commands in place and made the crontab run my script every minute. Then I could check it running using grep CRON /var/log/syslogs to see if my script ran. Once it was running how I wanted I removed the --dryrun and changed the frequency. Googling how CRON works is a good idea to make sure your scripts are running as needed.
Note: s3 has a limit on the number of free pushes you can have, CHECK THIS BEFORE JUST LEAVING IT RUNNING... BILLS CAN RUN AWAY FROM YOU IF YOU'RE SENDING LOTS OF DATA
I currently spend about $1 a year on my s3 pushes; it's not much but there's not a built-in thing for it yet so its worth it.
